Goodbye GitHub Pages
For a little over 3½ years this website was hosted on GitHub Pages. It used Jekyll (and still does) to compile the layouts, content, styles, etc. into this static website you’re reading now. For me, the greatest thing about static site generators like Jekyll is their simplicity. You write the code, you run a command, it spits out a website. The output you receive is all of the files necessary to view your website, assets all compiled and ready to go. The problem for me was that using GitHub Pages sometimes removed that key piece of simplicity.
New versions of Jekyll or other updates would be rolled out that either dropped or changed support for certain features. If you weren’t on top of these announcements you may have had to do some leg work to get your local build behaving exactly like GitHub Pages before knowing your deploys were working as expected.
While this didn’t cause me issues frequently, it was an annoyance that ruined the simplicity of static site generators. It also inevitably means that you’re bound to the constraints that GitHub Pages imposes and can’t use custom plugins or parsers as freely as you might like.
Hello Amazon S3
Amazon S3 provides static website hosting using a standard S3 bucket and some minor configuration. What drew me to move to S3 was the simplicity that mirrors a typical static site generator. Essentially with S3, you have some files (i.e. your static website files), you upload them to S3, you tell S3 you want the bucket to be a website, your website is online.
The added benefit is that because you’re responsible for putting the files in a bucket that will ultimately become your website, there is no limit to how you can use or configure your static site generator; you take the files it outputs locally and you put them on S3. Done. The site you previewed locally is the site that shows online. No compatibility concerns with whatever is building the site when you deploy, as with GitHub Pages.
Configuring S3 as a Static Website Host
Amazon has pretty good documentation on configuring a bucket to be a static website host. The steps are essentially what I followed for this website: create a bucket, configure the bucket, deploy the website. You can follow along the docs and use the AWS Management Console to create and configure the bucket.
We can also do it with code, so why not?
The aws-sdk gem supports managing
pretty much any resource on AWS including website buckets. The following code
configures the SDK gem and creates a bucket, then configures it for
static website hosting by creating a policy that allows access to all files in
the bucket. If you had more specific access requirements you could extend the
policy.
[default]
aws_access_key_id = <your default access key>
aws_secret_access_key = <your default secret key>source 'https://rubygems.org'
gem 'aws-sdk'
gem 'dotenv' # we'll use this later1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
require 'rubygems'
require 'bundler'
begin
Bundler.setup(:default, :development)
rescue Bundler::BundlerError => e
$stderr.puts e.message
$stderr.puts "Run `bundle install` to install missing gems"
exit e.status_code
end
require 'aws-sdk'
desc "Create website bucket on s3"
task :create do
# Perform operations in us-west-2 (or change to your preferred region)
client = Aws::S3::Client.new(region: 'us-west-2')
client.create_bucket(bucket: ENV['bucket'])
client.put_bucket_website({
bucket: ENV['bucket'],
website_configuration: {
index_document: {
suffix: "index.html",
}
}
})
client.put_bucket_policy({
bucket: ENV['bucket'],
policy: {
"Version" => "2012-10-17",
"Statement" => [
{
"Sid" => "AddPerm",
"Effect" => "Allow",
"Principal" => "*",
"Action" => "s3:GetObject",
"Resource" => "arn:aws:s3:::#{ENV['bucket']}/*"
}
]
}.to_json
})
client.put_object({
bucket: ENV['bucket'],
key: "index.html",
body: "Hello World!"
})
end
This small Rake task will put an accessible “Hello World” web page on S3.
The first 10-15 lines are just boilerplate gem loading. By default, the
aws-sdk gem will load credentials stored in your user’s home folder in
.aws/credentials.
The task can be invoked with rake create bucket=foobarbazbaz.com where bucket
is the domain name of the website. This isn’t the standard rake task argument syntax,
but I find using the environment variable syntax is more readable and easier to type.
- Line 17 sets up the SDK client and defines which region the bucket will be in.
- Line 19 creates the bucket with the name given.
- Lines 21-28 sets the basic configuration for a bucket website. This is effectively the same thing as clicking the “Enable website hosting” radio button in the management console and providing an index page value.
- Lines 30-44 create an access policy for the bucket. Since this is a static website bucket and all files need to be accessible by the browser, the policy allows access to all files using a wildcard.
- Lines 46-50 just puts a “Hello World!” index.html page in the bucket, to greet visitors.
The web page http://<your-bucket-name>.s3-website-<region>.amazonaws.com
will become available after running the Rake task. In this case, running the
task created http://foobarbazbaz.com.s3-website-us-west-2.amazonaws.com.
Of course, this step only needs to be done a single time. You should make sure whichever domain name you own that you want to host using S3 becomes the name of your bucket. This will be important when configuring a custom domain name.
Deploying the Website to S3
With the bucket created and configured, all that’s left to do to make this a
real website is put the files from the static site build into the bucket.
With Jekyll the built site is placed into a _site directory. The following Rake
task will iterate through each file in that directory, uploading each file to
the same path on S3.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
require 'rubygems'
require 'bundler'
begin
Bundler.setup(:default, :development)
rescue Bundler::BundlerError => e
$stderr.puts e.message
$stderr.puts "Run `bundle install` to install missing gems"
exit e.status_code
end
# Load region and S3 credentials from .env file, ex:
# REGION: us-west-2
# BUCKET: ronniemlr.com
# ACCESS_KEY_ID: <your access key>
# SECRET_ACCESS_KEY: <your secret key>
require 'dotenv'
Dotenv.load
desc "Deploy website to S3"
task :deploy do
puts "Building website"
`jekyll build`
puts "Deploying website"
require 'aws-sdk'
s3 = Aws::S3::Resource.new(region: ENV['REGION'],
access_key_id: ENV['ACCESS_KEY_ID'],
secret_access_key: ENV['SECRET_ACCESS_KEY'])
build = Pathname.new("_site")
Dir.glob("_site/**/*.*").each do |file|
# Glob can still pick up directories
next if File.directory?(file)
source = Pathname.new(file)
destination = source.relative_path_from(build)
object = s3.bucket(ENV['BUCKET']).object(destination.to_s)
object.upload_file(source)
end
puts "Website deployed"
end
This script could be improved to only deploy changed files since the last
commit, but for a small site like this one, deploying the whole thing doesn’t
take very long. Running the task with rake deploy puts the site online in
under a minute. Right now, I just run this command manually when I want to deploy
changes, but this could easily be called by a git hook.
Update: 2/4/17: I’ve since switched to using the excellent s3_website tool. It handles diffing for you and even asks you if you want to clean up old files on the s3 bucket.
Using a Custom Domain
The S3 documentation of course recommends that you use Amazon’s Route 53 service
to route your custom domain to your S3 bucket. The difference in the documented
setup and the one I landed on is that I don’t use Route 53. I also don’t create
a second bucket strictly for the www variant of this site, which Amazon
recommends you create in order to redirect that traffic to the main bucket.
Instead I use DNSimple (shameless referral link) which I’ve used to manage my domains for many years. Personally, I love DNSimple because they make it push-button easy to point your domain at S3. Assuming your bucket is named correctly it “Just Works™.”
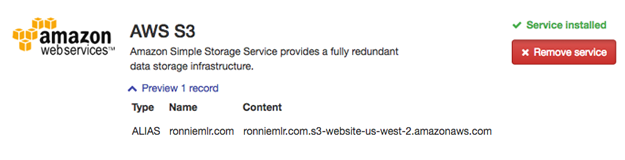
DNSimple will create an ALIAS record
for you that makes your domain map to the S3 bucket. For the www redirect,
I just use a URL record.
Both of these are actually special DNS record types created by
DNSimple to make
this stuff a no-brainer. One caveat is that URL redirect records don’t work for
HTTPS requests.
Conclusion
It might look like a lot of configuration, but it doesn’t take long. Overall I’m happy with this setup and glad to have more flexibility by having full control over the final build and deploy. Bye GH Pages! 👋